
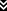
Triangle of Secure Code Delivery
Secure code delivery is the problem of getting software from its author to its users safely, with a healthy dose of mistrust towards the author and everything else in between.
We want to make sure that no attacker can modify the software as users download it in order to backdoor it or take control of their systems. More than that, we want to make it hard for the software's actual author to insert backdoors and selectively target users. This is important, because even if the author is absolutely trustworthy, they still might have been compromised, and with potentially millions of systems pulling code from them, we ought to have some sort of protection.
It's a difficult problem, one we haven't come close to solving. Especially so on new platforms like the Web, where entire applications are re-downloaded every time they are run.
The Triangle
Here's a Triangle, otherwise known as a list of three things, that I conjecture are necessary and sufficient for code delivery to be secure. The three points of the triangle are:
-
Reproducible Builds:
Given the application's source code, it should be possible to reproduce the distributed package exactly, down to contents that are known to vary benignly, such as build timestamps.
This property is important for auditing. A developer can sign both the source code and distributed binary package, but how does the user (or, more likely, a security auditor) know the source code actually represents the binary? To be sure, it has to be possible to re-create the binary package from the source exactly, or at least without unexplained differences. This provides some defense if the software's developers turn malicious or are successfully attacked.
-
Userbase Consistency Verification:
Users of the software should be able to check that the package they received is identical to the one that all other user received in a peer-to-peer (or otherwise decentralized) fashion. These packages should be available permanently in a public record.
This is the most important of the three properties. Simply put: Everyone gets the same thing. If you can guarantee that everyone gets an identical copy of the software, then it becomes impossible to hide a targeted attack. If an attacker wants to backdoor one user's software, they have to backdoor every user's software. This greatly increases the attacker's risk of being detected.
-
Cryptographic Signatures:
The software package, source code, and patches (changes) should be cryptographically signed by the upstream software source (i.e. the developers).
This serves to establish an anchor of trust to a person or organization responsible for maintaining the software. Without this property, a window of vulnerability exists before the software gets distributed widely enough for the Userbase Consistency Verification to be effective.
I conjecture that these three properties, if implemented correctly, are sufficient to disincentivize both large-scale attacks (i.e. the NSA wants to put a vulnerability in everyone's copy of Tor) and localized targeted attacks (i.e. the NSA wants to compromise a single user's software download to take control of their system).
Having just two of these properties is not enough:
-
Without Reproducible Builds:
Without Reproducible Builds, the software developer can be compromised and backdoors can be inserted into binaries prior to signing. With the binary distributed widely and in the public record, detection is still a risk for the attacker, but only if lots of people are looking very closely. With reproducible builds, detection becomes immediate by comparing the build-verified source code to the previous version.
-
Without Userbase Consistency Verification:
Without Userbase Consistency Verification, localized targeted attacks are much easier. This is especially true when the software developers themselves are malicious (or controlled by the NSA), and they want to serve backdoored copies to some users, but clean copies to most users.
-
Cryptographic Signatures:
Without this property, there's a window of opportunity for an attack to happen between the time when a new version of the software is released and when it becomes widely publicized and the Userbase Consistency Verification becomes effective. Any Userbase Consistency Verification system would probably depend on signatures simply in order to know who is authorized to release the next version of the software.
The Future
With these three properties in mind, can we build a secure code delivery system?
Cryptographic signatures are already available for most popular software. The Gitian project is making progress on Reproducible Builds and supports a limited kind of Userbase Consistency Verification. The Bitcoin cryptocurrency, being a decentralized append-only record, is evidence that full-scale Userbase Consistency Verification is possible, but can we make something reliable and easy to use for software? Perhaps it could work the way Perspectives or Convergence do for the SSL Certificate Authority system.
Can we build a secure code delivery system for the web, too? If we had a one built into our browsers, security would be a whole lot better. There would be no more compromised websites serving malware, and we could finally bring usable crypto, like LastPass, Cryptocat, miniLock, and GlobaLeaks to the masses.
I'm convinced that code delivery is the biggest challenge, with the most practical consequences, that we're facing today. Let's give it the attention it deserves. With these three principles, we can see a way forward.
